Reactの記法や概念について
目的
Reactで用いられる記法(useStateやProps)、概念(コンポーネントなど)について学ぶ。
JSX記法
JavaScriptファイルの中でHTMLのタグが書けるというもの。
重要なルールの1つとしてreturn以降は1つのタグで囲われている必要があるというものがあります。
例えば
index.js
import ReactDOM from "react-dom";
const App = () => {
return (
<h1>おはよう</h1>
<p>こんにちは</p>
);
};
ReactDOM.render(<App />, document.getElementById("root"));
とした場合、returnの中に2つのタグがあるためエラーを出してしまいます。
なので、以下のようにするとエラーを出さなくなります。
index.js
import ReactDOM from "react-dom";
const App = () => {
return (
<div> //<div>タグで一番外側を囲む
<h1>おはよう</h1>
<p>こんにちは</p>
</div>
);
};
ReactDOM.render(<App />, document.getElementById("root"));
その他には
<Fragment> //<Fragment>タグで囲む <h1>おはよう</h1> <p>こんにちは</p> </Fragment> <> //<>タグで囲む <h1>おはよう</h1> <p>こんにちは</p> </>
などがあります。
尚、Fragmentタグを用いる際は
import { Fragment } from "react";
というようにimportする必要があります。
コンポーネントについて
Reactの開発では画面の要素を様々な粒度のコンポーネントに分割することで再利用性や保守性を高めるのが基本となります。(1つのファイルに全て書かず小分けにしていく)
これを理解していくために例えば次のようなフォルダを用意します。
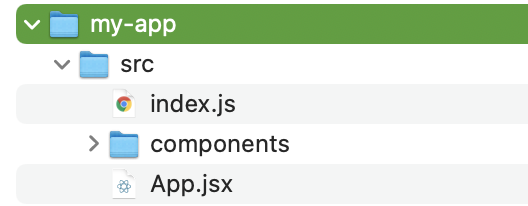
ここでは新たにmy-app/src/App.jsxを追加したところです。
App.jsx にこのように記述します。
const App = () => {
return(
<> //先程説明した空タグを用いてます
<h1>おはよう</h1>
<p>こんにちは<p>
</>
);
};
この関数コンポーネントを他のファイルでも使えるようにするためにはexportする必要があります。
export const App = () => {
return(
<> //先程説明した空タグを用いてます
<h1>おはよう</h1>
<p>こんにちは<p>
</>
);
};
これで他のファイルでも使えるようになりました。他のファイルで使用する際にはimportする必要があります。
index.js(jsx記法の説明で用いたファイル)
import ReactDOM from "react-dom";
import { App } from "./App"; //追加
//ここから
const App = () => {
return(
<> //先程説明した空タグを用いてます
<h1>おはよう</h1>
<p>こんにちは<p>
</>
);
};
//ここまで削除(App.jsに切り出したので)
ReactDOM.render(<App />, document.getElementById("root"));
これでコンポーネント化ができました。
イベントやスタイルについて
例としてボタンを押した時のイベントonClickについては以下のように行います。
export const App = () => {
const onClickButton = () => {
alert();
};
return (
<>
<h1>おはよう</h1>
<p>こんにちは</p>
<button onClick={onClickButton}>ボタン</button>
</>
);
};
尚、returnの中でJavaScriptで定義した関数を使う時は{}で囲むようにします。
次にスタイル(CSS)のあてかたについてです。
Reactでは各タグにstyle属性を記述することでスタイルを適用できます。ここで注意点ですがCSSの各要素はJavaScriptのオブジェクトとして記述します。
例として文字の色を黄色に変更したい場合は以下のようになります。
export const App = () => {
//省略
return (
<>
<h1 style={{color: "yellow"}}>おはよう</h1>
<p>こんにちは</p>
</>
);
};
JavaScriptを書くので、style={}としており{}の中でCSSを書くのでさらに{}が入り、結果としてstyle={{}}となります。
先程述べたようにCSSの各要素はJavaScriptのオブジェクトとして記述するのでyellowではなく"yellow"と記述します。
またタグ内で定義するのではなく事前に定義して変数にいれたものを使うこともできます。
export const App = () => {
//省略
//CSSオブジェクトを定義
const contentStyle = {
color: "green",
fontSize: "30px",
};
return (
<>
<h1 style={{color: "yellow"}}>おはよう</h1>
<p style={contentStyle}>こんにちは</p> //style={変数名}
</>
);
};
Propsについて
Propsとはコンポーネントに渡す引数のようなもので、コンポーネントは受け取ったPropsに応じて表示するスタイルや内容を変化させます。
以下で例を見ていきます。
まずはmy-app/src/components/ColoredMessage.jsxというコンポーネントファイルを作成します。
ColoredMessage.jsx(これがApp.jsxからProps(中身は色とテキスト)を受け取って色付きの文字を返すコンポーネント)
//引数であるpropsの中にApp.jsxから送られてきたcolorとmessageが入っている
export const ColoredMessage = (props) => {
const contentStyle = {
color: props.color,
fontSize: "20px",
};
return <p style={contentStyle}>{props.message}</p>;
};
App.jsx
import { ColoredMessage } from "./components/ColoredMessage";
export const App = () => {
const onClickButton = () => {
alert();
};
return (
<>
<ColoredMessage color="yellow" message="おはよう" /> //ここでpropsとして情報を渡しています
<ColoredMessage color="red" message="こんにちは" />
</>
);
};
これで一つのコンポーネント(ここではColoredMessage)を複数使いページを表示することができます。
そしてもう一つPropsを使う上で用いるのがchildrenというものです。
実際にchildrenを用いて先程のコードを確認すると以下となります。
App.jsx
<ColoredMessage color="yellow" message="おはよう" /> //変更前 <ColoredMessage color="yellow">おはよう</ColoredMessage> //変更後
このように
省略
return <p style={contentStyle}>{props.message}</p>; //変更前
return <p style={contentStyle}>{props.children}</p>; //変更後
今はchildrenのメリットがわかりづらいですが、今後複雑なコンポーネントを組む際に便利となるようです。
State(useState)
Stateとはコンポーネントの状態を表す値です。
状態とは例えばボタンを押す、エラーがあるorない、モーダルが開いているor開いていないなどがあります。
これらをStateを用いて管理します。
「状態を表す」とは言い換えれば「変数をもつ」でありコンポーネントの中でイベント実行時などに更新処理を行うことで動的なアプリケーションを表現します。
今回はReact Hooksと呼ばれる機能の中のuseStateを用いてStateを考えます。
使用するにはまずuseStateをimportする必要があります。
import { useState } from "react";
useStateの書式は以下のようになります。
const [ num, setNum ] = useState();
配列の中で1つ目にState変数(状態を持つ変数)を、2つ目にそれを更新するための関数を設定します。
useStateは関数なので用いる際は()をつけます。State変数に初期値を置きたい時はこの()内に設定します。
例えばボタンを押下時にカウントアップする機能を実装する場合は以下のようにできます。
import { useState } from "react";
export const App = () => {
const [ num, setNum ] = useState(0); //初期値に0を置いています
const onClickButton = () => {
setNum(num + 1);
};
return (
<>
<button onClick={onClickButton}>ボタン</button>
<p>{num}</p> //ここで変数を表示します
</>
);
};
これで以下のような初期状態のボタンができました。

「ボタン」を押下すると変数に+1されるのでカウントの数値が変化していきます。

以上でReactで頻出する基本の書式をまとめてみました。他にも多くの表現方法があると思いますがそれは実際にアプリを作る際にさらに調べてみようと思います。
Reactの基本書式について
目的
Reactを学習していくにあたり、よく用いられるJavaScriptの記法を押さえておくことで内容の理解をスムーズに行えるようにする。
const、letでの変数宣言
従来のJavaScriptでの変数宣言はvarを用いていました。
var foo = "bar";
特徴として上書き可能、再宣言可能であるということです。
var foo = "bar"; console.log(foo); // bar // 上書き foo = "barを上書き"; console.log(foo); // barを上書き // 再宣言 var foo = "barを再宣言" console.log(foo); // barを再宣言
上記の例はエラーを出すことなく実行されます。 しかし、上書き可能、再宣言可能というのはプロジェクトの規模が大きくなると意図せず起こしてしまうことがあるのでES2015では新たな変数宣言の方法として constとletが追加されました。
letでの変数宣言
let foo = "bar"; console.log(foo); // bar
書き方はvarと同じです。上書き可能、再宣言は不可能であるという特徴があります。
constでの変数宣言
const foo = "bar"; console.log(foo); // bar
これも書き方はvarと同じです。上書き、再宣言ともに不可能という特徴があります。
上記でconstは上書き不可能と述べましたが変数の種類によっては値を変更していくことが可能です。
変更可能な変数 オブジェクト型
・オブジェクト
・配列
・関数
など
変更不可能な変数 プリミティブ型
・真偽値(boolean):true/false
・数値(number) :1,19
・文字列(string) :"あいうえお"
・null :値なし
など
//オブジェクトを定義
const foo = {
name: "織田",
age: 50,
};
console.log(foo); // {name: "織田", age: 50}
foo.name = "豊臣";
console.log(foo); // {name: "豊臣", age: 50}
プロパティ値が変更できている
foo.address = "日本";
console.log(foo); //{name: "豊臣", age: 50, address: "日本"}
プロパティが追加できている
React開発で使用するのはconstがほとんど。Stateで管理せず処理の中で値を上書きしていくような変数のみletを使うとのことです。
テンプレート文字列
文字列の中で変数を展開するための記法です。
従来は以下のように+を用いていました。
const name = "織田"; const animal = "犬"; //文字列の中で変数を用いる。 const message = "私の名前は"+ name +"です。好きな動物は"+ animal +"です。"; console.log(message); // 私の名前は織田です。好きな動物は犬です。
これをテンプレート記法を用いると以下となります。
const message = `私の名前は${name}です。好きな動物は${animal}です。`;
// 結果は従来のものと同じになります。
注意点としてテンプレート文字列を使用する場合は「`(バッククォート)」で文字列を囲みます。
アロー関数
//従来の関数記法(functionを用いる)
function foo(value) {
return value;
}
console.log(foo("barです")); // barです
これをアロー関数で表記すると以下のようになります。
const foo = (value) => {
return value;
};
console.log(foo("barです")); //barです
アロー関数の書き方にはいくつか省略記法があります。
省略記法1
// 引数が1つのときは()を省略できる
const foo = value => {
return value;
};
console.log(foo("barです")); // barです
//引数が2つ以上の時は()をつけないといけません。
省略記法2
//処理を単一行で返却する場合は波カッコ{}とreturnを省略できる
const foo = (num1, num2) => num1 - num2;
console.log(foo(23,10)); // 13
また、返却値が複数行に及ぶ場合には()で囲むことで単一行のようにまとめて返却することができます。これで先程のreturnを省略できます。
const foo = (val1, val2) => (
{
name: val1,
address: val2,
}
)
console.log(foo("織田", "日本")); // {name: "織田", address: "日本"}
これらは今後Reactの中で良く出てきます。基本形だけでなく省略形も覚えておくことで関数を表していることをすぐに理解できるようにします。
分割代入{} []
通常、オブジェクトから値を抽出する際は以下のように行います。
const book = {
title: "Reactの教科書",
price: 1800,
};
const introduction = `この本のタイトルは${book.title}です。価格は${book.price}円です。`;
console.log(introduction); //この本のタイトルはReactの教科書です。価格は1800円です。
このように基本は変数名.プロパティと書いて値を抽出します。しかし変数名が長いと毎回このように書くのは大変です。その時に分割代入を用いて出力する方法があります。
const book = {
title: "Reactの教科書",
price: 1800,
};
//オブジェクトの分割代入
const { title, price } = book;
const introduction = `この本のタイトルは${title}です。価格は${price}円です。`;
console.log(introduction); //この本のタイトルはReactの教科書です。価格は1800円です。
このように{}を変数宣言部に使用することでオブジェクト内から一致するプロパティを抽出することができます。
また
const { price } = book;
のように一部を取り出すのでも大丈夫です。
配列の分割代入の場合は以下のように行います。
const book = ["Reactの教科書", 1800];
//配列の分割代入
const [title, price] = book;
const introduction = `この本のタイトルは${title}です。価格は${price}円です。`;
console.log(introduction); //この本のタイトルはReactの教科書です。価格は1800円です。
デフォルト値 =
デフォルト値の設定は、関数の引数やオブジェクトの分割代入時に使用して、値が存在しない場合の初期値を設定することが可能になります。
まずは関数の引数についてです。
//デフォルト値を使わない場合(実行時に引数を渡さなかった場合
const book = (title) => console.log(`この本のタイトルは${title}です。`);
book(); //この本のタイトルはundefinedです。
このように引数を指定しなかった場合undefinedが挿入されます。
ではデフォルト値を設定するとどうなるでしょうか。
const book = (title = "匿名") => console.log(`この本のタイトルは${title}です。`);
book(); //この本のタイトルは匿名です。
book("Reactの教科書"); //この本のタイトルはReactの教科書です。
引数の後ろに=で値を記述することでデフォルト値を使用できます。引数を指定しない場合はデフォルト値が入り、引数を指定した場合はその値が入っているのがわかると思います。
次に分割代入時のデフォルト値設定する場合です
const myProfile = {
age : 19,
}
const { name: "ゲスト" } = myProfile;
const message = `ようこそ、${name}さん。`;
console.log(message); //ようこそ、ゲストさん。
このように変数名の後ろに=で値を設定しておくとプロパティが存在しない場合に設定する値を指定できます。
スプレット構文 ...
スプレット構文は「...」という形でドットを3つ配列の前におくことで使用できます。これで配列内部の要素を順番に展開します。
例
const arr1 = [1, 2]; console.log(arr1); // [1,2] console.log(...arr1); // 1 2
またスプレット構文には要素をまとめるという使い方もできます。
例
const arr1 = [2,4,6,8,10]; //分割代入時に残りを「まとめる」 const [num1, num2, ...arr2] = arr1 console.log(num1); // 2 console.log(num2); // 4 console.log(arr2); // [6,8,10]
これらを生かして要素のコピー、結合を行うこともできます。
例
const arr1 = [1, 2]; //スプレット構文でコピー const arr2 = [... arr1]; console.log(arr1); // [1, 2] console.log(arr2); // [1, 2]
このように簡単にコピーすることができました。
結合についても以下のようにできます。
const arr1 = [1,2]; const arr2 = [3,4]; //スプレット構文で結合 const arr3 =[...arr1, ...arr2]; console.log(arr3); //[1,2,3,4]
map, filter
この2つは配列の処理で使います。
まずはmap関数から見ていきます。map関数は配列を順番に処理してその結果を配列として受け取るものです。
//配列を定義
const foo = ["織田", "豊臣", "徳川"];
//引数(name)に配列の値が設定される。returnで返却する。
const bar = foo.map((name) => {
return name;
});
console.log(bar); // ["織田", "豊臣", "徳川"]
このように配列.map()とすることでnameのところに配列の値が順に入っていきます。上記の例だとreturn name;なので、順番に入れた配列の値がそのまま返却されます。
次はfilter関数についてです。
filter関数はmap関数とほとんど使い方が同じですが、returnの後に条件式を記述して一致するもののみが返却される関数となる点が異なります。
例(配列から偶数のみを取り出す)
const numArr = [1,2,3,4,5];
const newNumArr = foo.filter((num)=>{
return num % 2 === 0;
});
console.log(newNumArr); // [2,4]
このように「配列の中から特定の条件に一致するもののみを取り出して処理したい」場合にはfilter関数を使うようにします。
三項演算子 :
三項演算子はif ~ else ~文と同じ意味合いですが簡潔に書けるので使い分けて用います。
基本書式は
ある条件? 条件がtrueの時の処理 : 条件がfalseの時の処理
というように「?」と「:」を使って処理を分岐させます。
例
const checkSumOver500 = (num1, num2) => {
return num1 + num2 > 500 ? "500を超えています" : "500以下です";
}
console.log(checkSumOver500(300, 400)); // 500を超えています
console.log(checkSumOver500(100, 200)); // 500以下です
このように簡単に分岐処理を書くことができます。
今後Reactの学習を進めるにあたりこれらの書式は欠かすことのできない知識なのでまとめました。
参考図書: www.sbcr.jp
SQL ゼロからはじめるデータベース操作のアウトプット2
前回に続いてアウトプットしていきます。
データの登録(INSERT文)
INSERT文の基本構文
INSERT INTO <デーブル名> (列1, 列2, 列3, ・・・) VALUES (値1,値2,値3, ・・・);
例
INSERT INTO ShohinIns (shohin_id, shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('0001', 'Tシャツ', '衣服', 1000, 500, '2009-09-20');
※列名や値をカンマで区切って、外側を()でくくった形式をリストと呼びます。
上記例だと
列リスト→(shohin_id,shohin_mei,shohin_bunrui,hanbai_tanka,shiire_tanka,torokubi)
値リスト→('0001','Tシャツ','衣服',1000,500,'2009-09-20')
※INSERT文は、基本的に1回で1行を挿入します。複数の値を挿入したい場合は、原則的にその行数だけINSERT文も繰り返し実行する必要があります。
列リストの省略
テーブル名の後の列リストは、テーブルの全列に対してINSERTを行う場合、省略することができます。このとき、VALUES句の値が暗黙のうちに、左から順に各列に割り当てられます。そのため、以下の2つは同じデータを挿入することを意味します。
-- 列リストあり
INSERT INTO ShohinIns (shohin_id, shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES ('0005', '圧力鍋', 'キッチン用品', 6800, 5000, '2009-01-15');
-- 列リストなし
INSERT INTO ShohinIns VALUES ('0005', '圧力鍋', 'キッチン用品', 6800, 5000, '2009-01-15');
デフォルト値を挿入する
テーブルの定義時にDEFAULT値を設定するとINSERT文の列の値として自動的に割り当てられる。
例としてShohinInsテーブルを作成する際にデフォルト制約をつけます。
CREATE TABLE ShohinIns (shohin_id CHAR(4) NOT NULL, (略) hanabi_tanka INTEGER DEFAULT 0, -- 販売単価のデフォルト値を0に設定 (略) PRIMARY KEY (shohin_id));
これでデフォルト値の準備ができました。では実際に設定したデフォルト値を使ってみます。
使い方①明示的にデフォルト値を挿入する
VALUES句にDEFAULTキーワードを指定する。
INSERT INTO ShohinIns (shohin_id, shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) VALUES('0007', 'おろしがね', 'キッチン用品', DEFAULT, 790, '2009-04-28');
これでshohin_id=0007の行を選択した場合、販売単価=0として割り当てられた行を返します。
使い方②暗黙的にデフォルト値を挿入する
デフォルト値が設定されている列を列リストからもVALUESからも省略する。
INSERT INTO ShohinIns (shohin_id, shohin_mei, shohin_bunrui,shiire_tanka, torokubi) VALUES ('0007', 'おろしがね', 'キッチン用品', 790, '2009-04-28');
上の例ではhanbai_tanka列を省略しています。
この場合もhanbai_tankaにはデフォルト値の0が挿入されます。
では、この2つの使い方のどちらを使うのが良いかについては使い方①を筆者はお勧めしています。それはぱっと見て何がデフォルト値に利用されてるかわかりやすいからです。
ほかのテーブルからデータをコピーする
あらかじめShohinCopyテーブルを作成しているものとします。
このShohinCopyテーブルに、前章まで使っていたShohinテーブルのデータを挿入します。
-- 商品テーブルのデータを商品コピーテーブルへコピー INSERT INTO ShohinCopy (shohin_id, shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi) SELECT shohin_id, shohin_mei, shohin_bunrui, hanbai_tanka, shiire_tanka, torokubi FROM Shohin;
このINSERT・・・SELECT文を実行すると、たとえば元のShohinテーブルに8行のデータが入っていたとすれば、ShohinCopyテーブルにも全く同じ8行のデータが追加されます。
他にもこのINSERT文内のSELECT文には、WHERE句やGROUP BY句などを使うこともできます。
例えば以下のようなShohinBunruiテーブルがあったとする。
-- 商品部類ごとにまとめたテーブル CREATE TABLE ShohinBunrui (shohin_bunrui VARCHAR(32) NOT NULL, sum_hanbai_tanka INTEGER , sum_shiire_tanka INTEGER , PRIMARY KEY (shohin_bunrui));
これは商品分類ごとに販売単価の合計と仕入単価の合計を保持するためのテーブルです。ここに、Shohinテーブルからデータを挿入するならば以下のようなINSERT・・・SELECT文を使います。
INSERT INTO ShohinBunrui (shohin_bunrui, sum_hanbai_tanka, sum_shiire_tanka) SELECT shohin_bunrui, SUM(hanbai_tanka), SUM(shiire_tanka) FROM Shohin GROUP BY shohin_bunrui;
これで最初の商品分類テーブルにShohinテーブルの商品分類ごとの販売単価の合計、仕入単価の合計が挿入されることとなる。
データの削除
データの削除方法は、大きく分けて2つあります。
①DROP TABLE文によって、テーブルそのものを削除する
②DELETE文によって、テーブル(入れ物、容器)は残したまま、テーブル内のすべての行を削除する。
ここでは②について詳しく見ていきます。
構文
DELETE FROM <テーブル名>;
この構文の場合は指定したテーブルの全ての行を削除します。
次に削除対象を指定したDELETE文を見ていきます。
構文
DELETE FROM <テーブル名> WHERE <条件>;
例
DELETE FROM Shohin WHERE hanbai_tanka >= 4000;
データの更新(UPDATE文)
UPDATE文はテーブルにINSERT文でデータを登録した後、変更したいときなどに使います。
構文
UPDATE <テーブル名> SET <列名> = <式>;
例(登録日をすべて「2009年10月10日」に変更する)
UPDATE Shohin SET torokubi = '2009-10-10';
※尚、更新前にNULLだった部分にも更新した内容が反映されます。
条件を指定したUPDATE文
構文
UPDATE <テーブル名> SET <列名> = <式> WHERE <条件>;
例(商品分類が「キッチン用品」の行のみ販売単価を10倍に変更)
UPDATE Shohin SET hanbai_tanka = hanbai_tanka * 10 WHERE shohin_bunrui = 'キッチン用品';
NULLで更新する
この場合は代入式の右辺にNULLを指定してあげることで可能となります。又、この処理をNULLクリアと呼びます。
例(商品IDが「0008」のボールペンの登録日をNULLに変更)
UPDATE Shohin SET torokubi = NULL WHERE shohin_id = '0008';
複数列の更新
複数の列を更新対象として記述することが可能です。
例えば以下のようなUPDATE文があったとします。
-- 1回のUPDATEで1列だけ更新する UPDATE Shohin SET hanbai_tanka = hanbai_tanka * 10 WHERE shohin_bunrui = 'キッチン用品'; UPDATE Shohin SET shiire_tanka = shiire_tanka / 2 WHERE shohin_bunrui = 'キッチン用品';
これでも正しく更新されますが、これを1つのUPDATE文にまとめることもできます。それは下記の2パターンがあります。
方法①
-- 列をカンマ区切りで並べる
UPDATE Shohin
SET hanbai_tanka = hanbai_tanka * 10,
shiire_tanka = shiire_tanka / 2
WHERE shohin_bunrui = 'キッチン用品';
方法②
-- 列をカッコ()で囲むことによるリスト表現 UPDATE Shohin SET (hanbai_tanka, shiire_tanka) = (hanbai_tanka * 10,shiire_tanka / 2) WHERE shohin_bunrui = 'キッチン用品';
トランザクション
トランザクションは「セットで実行されるべき1つ以上の更新処理の集まりのこと」です
トランザクションを作るには以下のような構文を用います。
トランザクション開始文; DML文①; DML文②; DML文③; ・ ・ ・ トランザクション終了文(COMMITまたはROLLBACK);
上記のトランザクション開始文はDBMSによって変わります。
SQL Server、PostgreSQLの場合
BEGIN TRANSACTION
MySQLの場合
START TRANSACTION
Oracle、DB2の場合
ない
尚、これらはあくまで各DBMSによって変化する方言であり標準SQLにおいては「トランザクションは暗黙的に開始され、明示的な開始ステートメントは存在しない」と明記されています。
処理の終了について
明示的な開始ステートメントがないのに対し、トランザクションの終わりはユーザーが指示する必要があります。
終わりには処理の確定と処理の取り消しがあります。
処理の確定にはCOMMITを用います。これはファイルでいうところの「上書きして保存」にあたります。コミットしてしまうと、トランザクション開始前の状態に戻すことはできないので注意が必要です。
次に処理の取り消しにはROLLBACKを用います。これはファイルでいうところの「保存せずに終了」にあたります。
例
BEGIN TRANSACTION; -- カッターシャツの販売単価を1000円値引き UPDATE Shohin SET hanbai_tanka = hanbai_tanka - 1000 WHERE shohin_mei = 'カッターシャツ'; -- Tシャツの販売単価を1000円値上げ UPDATE Shohin SET hanbai_tanka = hanbai_tanka + 1000 WHERE shohin_mei = 'Tシャツ'; ROLLBACK;
「;」は各UPDATE文毎につける。
ロールバック(処理の取り消し)は保存せずに終了するのであればわざわざ記述する必要性がわからない。後でわかったら追記しようと思います
SQL ゼロからはじめるデータベース操作のアウトプット1
前回、データベース設計を学びましたがデータベースを操作できなければ意味がないと思いSQLを学びました。 今回は自分用の備忘録としてアウトプットしていきます。
おさらいですが「データベースとは何を指すでしょうか?」
ここでは「大量の情報を保存し、コンピュータから効率よくアクセスできるように加工したデータの集まりのこと」としています。
又、データベースを管理するコンピュータシステムのことを、「データベース管理システム(DBMS)」と呼びます。
DBMSにはいろんな種類がありますが今回は現在最も広く利用されているリレーショナルデータベース(関係データベース)を学びます。
代表的なリレーショナルデータベースとしては以下の5つがあります。
Oracle Database:Oracle社のRDBMS
SQL Server:Microsoft社のRDBMS
DB2:IBM社のRDBMS
PostgreSQL(ポストグレスキューエル):オープンソースのRDBMS
MySQL:オープンソースのRDBMS(2010年からOracle社が開発元)
SQLを学ぶ上で「標準SQL」も頭に入れておいた方が良いかもしれません。
ISO(国際標準化機構)に準拠したSQLのことです。以前はRDBMSごとの「方言」でSQL分を書いていました。実務においても方言で書かれたSQL文に遭遇することもあるので読めるようにはしておいた方が良いみたいです。
SQL文の種類
DDL(データ定義言語)
CREATE:データベースやテーブルなどを作成する
DROP:データベースやテーブルなどを削除する
ALTER:データベースやテーブルなどの構成を変更する
DML(データ操作言語)
SELECT:テーブルから行を検索する
INSERT:テーブルに新規行を登録する
UPDATE:テーブルの行を更新する
DELETE:テーブルの行を削除する
DCL(データ制御言語)
COMMIT:データベースに対して行った変更を確定する
ROLLBACK:データベースに対して行った変更を取り消す
GRANT:ユーザに操作の権限を与える
REVOKE:ユーザから操作の権限を奪う
SQLの基本的な記述ルール
・文末に「;」(セミコロン)をつける
・大文字、小文字は区別されない
SELECTもslectも同じように解釈されます。書内では以下のルールで記述しています。
・キーワードは大文字
・テーブル名は頭文字のみ大文字
・その他(列名など)は小文字
その他留意点
SQL文の中にじかに書く文字列や日付、数値を定数と呼びます。
文字列や日付は'abc'のように「'」(シングルクォーテーション)で囲む
一方、数値は記号で囲む必要は無い。
単語は半角スペースか改行で区切る。
実践
以後は構文と例を用いて実際のSQL文を記述していきます。
データベースの作成
CREATE DATABASE <テーブル名>;
例
CREATE DATABASE shop;
テーブルの作成
構文
CREATE TABLE <テーブル名>
(<列名1> <データ型> <この列の制約>,
<列名2> <データ型> <この列の制約>,
・
・
<このテーブルの制約1>, <このテーブルの制約2>,......);
例
CREATE TABLE Shohin (shohin_id CHAR(4) NOT NULL, shohin_mei VARCHAR(100) NOT NULL, shohin_bunrui VARCHAR(32) NOT NULL, hanbai_tanka INTEGER , shiire_tanka INTEGER , torokubi DATE , PRIMARY KEY (shohin_id));
尚、命名のルールとして
データベースやテーブル、列などの名前に使って良い文字は次の3種類
・半角のアルファベット
・半角の数字
・アンダーバー(_)
又、名前の最初の文字は「半角のアルファベット」にすること。
1shohinなど数字で始めることは出来ません。
テーブルの削除
DROP TABLE <テーブル名>;
例
DROP TABLE Shohin;
※削除したテーブルとそのデータは復活できませんので注意が必要です。
テーブル定義の変更
ALTER TABLE <テーブル名> ADD COLUMN <列の定義>;
例
ALTER TABLE Shohin ADD COLUMN shohin_mei_kana VARCHAR(100);
これはShohinテーブルにshohin_mei_kana(商品名(カナ))という100桁の可変長文字列を入れる列を追加することを指します。
又、テーブルの列を削除する際には以下となります。
ALTER TABLE <テーブル名> DROP COLUMN <列名>;
テーブルへのデータ登録
-- DML :データ登録
BEGIN TRANSACTION;
INSERT INTO Shohin VALUES ('0001', 'Tシャツ', '衣服', 1000, 500, '2009-09-20');
INSERT INTO Shohin VALUES ('0002', '穴あけパンチ', '事務用品', 500, 320, '2009-09-11');
・
・
・
INSERT INTO Shohin VALUES ('0008', 'ボールペン', '事務用品', 100, NULL, '2009-11-11');
COMMIT;
テーブルの訂正
ALTER TABLE Sohin RENAME TO Shohin;
ALTER TABLE <変更前の名前> TO <変更後の名前>とする。
SELECT文の基本
SELECT <列名>, ・・・・ FROM <テーブル名>;
例
SELECT shohin_id, shohin_mei, shiire_tanka FROM Shohin;
全ての列を出力する場合は
SELECT *(アスタリスク) FROM <テーブル名>;
列に別名をつける(後から頻出する)
ASキーワードを使って、列に別名をつけることができる。
SELECT shohin_id AS id,
shohin_mei AS namae,
shiire_tanka AS tanka
FROM Shohin;
尚、別名には日本語を使うこともできる。その場合は別名をダブルクォーテーション(")で囲む。
SELECT shohin_id AS "商品ID",
shohin_mei AS "商品名",
shiire_tanka AS "仕入単価"
FROM Shohin;
結果から重複行を省く
SELECT DISTINCT shohin_bunrui FROM Shohin;
SELECT句でDISTINCTを使う。
重複行を省く際、複数の行にNULLがある場合は1つのNULLとして扱われる。
又、
SELECT DISTINCT shohin_bunrui, torokubi FROM Shohin;
とすれば2つの行の組み合わせで全く同じものを省く。
WHERE句による行の選択
SELECT <列名>, ・・・ FROM <テーブル名> WHERE <条件式>;
とするとWHERE句に指定した条件に合う行だけが選択される。
例
SELECT shohin_mei, shohin_bunrui FROM Shohin WHERE shohin_bunrui = '衣服';
処理の順番はWHERE句で指定した条件に合う行をまず選択し、その後にSELECT句で指定された列を返す。句の順番を入れ替えるとエラーになるので注意。
コメントの書き方
1行コメント
「--」の後に記述する。
複数行のコメント
「/」と「/」で囲む。
例
-- このSELECT文は、結果から重複を無くします。 SELECT DISTINCT shohin_id, shiire_tanka FROM Shohin;
例2
/* このSELECT文は、 結果から重複を無くします。*/ SELECT DISTINCT shohin_id, shiire_tanka FROM Shohin;
※例では冒頭にコメントを入れていますがSQL文の途中に差し込むこともできます。
算術演算子と比較演算子
まずは算術演算子から
SQL文の中には+,-,*,/を用いて計算ができる。
しかし、NULLには注意が必要でNULLが含まれる計算は、全てNULLになる。
5 + NULL = NULLなど。
次に比較演算子
・ = : 〜と等しい
・ <> : 〜と等しくない
・ >= : 〜以上
・ > : 〜より大きい
・ <= : 〜以下
・ < : 〜より小さい
これらの比較演算子は文字、数値、日付など、ほぼ全てのデータ型の列、値を比較することができる。
例
SELECT shohin_mei, shohin_bunrui, hanbai_tanka FROM Shohin WHERE hanbai_tanka >= 1000;
尚、以下のように計算した結果を比較演算子で比較することも可能。
SELECT shohin_mei, hanbai_tanka, shiire_tanka FROM Shohin WHERE hanbai_tanka - shiire_tanka >= 500;
※NULLは比較演算子の対象になりません。
NULLである行を選択する際には
SELECT shohin_mei, shiire_tanka FROM Shohin WHERE shiire_tanka IS NULL;
NULLでない行を選択する際には
SELECT shohin_mei, shiire_tanka FROM Shohin WHERE shiire_tanka IS NOT NULL;
論理演算子について
NOT演算子
例
SELECT shohin_mei, shohin_bunrui, hanbai_tanka FROM Shohin WHERE NOT hanab_tanka >= 1000;
これは
SELECT shohin_mei, shohin_bunrui FROM Shohin WHERE hanbai_tanka < 1000;
と同じ。NOT演算子を使わなくても良い場面も多く、あまり使われません。
AND演算子
SELECT shohin_mei, shiire_tanka FROM Shohin WHERE shohin_bunrui = 'キッチン用品' AND hanbai_tanka >= 3000;
のように使います。両辺の条件が成り立つものを結果として返します。
対してOR演算子はANDと同じように使いますが、
両辺の条件のうち、どちらか一方、あるいは両方が成り立つものを結果として返します。
※ANDはORより強いので、ORを優先させるときは()で囲い込みます。
例
SELECT shohin_mei, shohin_bunrui, torokubi
FROM Shohin
WHERE shohin_bunrui = '事務用品'
AND ( torokubi = '2009-09-11'
OR torokubi = '2009-09-20');
これで「登録日が2009-09-11または2009-09-20」かつ「商品分類が事務用品」のものを検索します。
テーブルを集約して検索する
集約関数
COUNT:テーブルのレコード数(行数)を数える
SUM:テーブルの数値列のデータを合計する
AVG:テーブルの数値列のデータを平均する
MAX:テーブルの任意の列のデータの最大値を求める
MIN:テーブルの任意の列のデータの最小値を求める
例
SELECT COUNT(*) FROM Shohin;
と用いる。 例(販売単価の合計を求める)
SELECT SUM(hanbai_tanka) FROM Shohin;
例2(販売単価と仕入単価の合計を求める)
SELECT SUM(hanbai_tanka), SUM(shiire_tanka) FROM Shohin;
2つあるときは「,」で区切る。 ※集約関数はNULLを除外する。ただし「COUNT(*)」は例外的にNULLを除外しない。 他の集約関数も使い方は同様。
重複値を除外する場合
SELECT COUNT(DISTINCT shohin_bunrui) FROM Shohin;
というように引数内にDISTINCTを用いる。
テーブルをグループに切り分ける
GROUP BY句による集約
SELECT <列名1>,<列名2>,<列名3>,・・・ FROM <テーブル名> GROUP BY <列名1>,<列名2>,<列名3>,・・・・;
例えば商品分類ごとの行数を数える際
SELECT shohin_bunrui, COUNT(*) FROM Shohin GROUP BY shohin_bunrui;
となる。
※集約キー(GROUP BY句の引数)にNULLが含まれている場合一括してNULLというグループに分類される。
SELECT文の記述順
1.SELECT→2.FROM→3.WHERE→4.GROUP BY
実行順序は記述順と異なり
FROM→WHERE→GROUP BY→SELECT
なので、
SELECT shiire_tanka, COUNT(*) FROM Shohin WHERE shohin_bunrui = '衣服' GROUP BY shiire_tanka;
ではまず商品分類=衣服の行に絞り込まれてから仕入れ単価ごとにグループ分けされる。
間違えやすい点
①SELECT句に余計な列を書いてしまう。
COUNTのような集約関数を使った場合、SELECT句に書くことができる要素が非常に限定され、以下の3つしかSELECT句に書けない
・定数(123という数値や'テスト'という文字列)
・集約関数
・GROUP BY句で指定した列名(つまり集約キー)
「GROUP BY句を使うときは、SELECT句に集約キー以外の列名を書けない」と覚えておく
例えば
SELECT shohin_mei, shiire_tanka, COUNT(*) FROM Shohin GROUP BY shiire_tanka;
はエラーになる。 shohin_meiという列名は、GROUP BY句にないので。
②GROUP BY句に列の別名を書いてしまう。 ASで別名をつけることができるが、それをGROUP BY句で使うとエラーになる。
SELECT shohin_bunrui AS sb, COUNT(*) FROM Shohin GROUP BY sb;
のようにしても処理順序がGROUP BY→SELECTなので、SELECT句で別名をつけてるsbはGROUP BY句の時点では存在しないのでエラーになる。
③WHERE句に集約関数を書いてしまう。
集約関数を書ける場所はSELECT句とHAVING句(とORDER BY句)だけ
集約した結果に条件を指定する(HAVING句)
集約した結果に対して条件指定をしたい。
条件指定といえばWHERE句が出てくるかもしれないがWHERE句はレコード(行)に対してしか条件を指定できない。
グループに対する条件指定(例「含まれる行数が2行」「平均値が500」など)はHAVING句を用いる。
構文
SELECT <列名1>,<列名2>,<列名3>,・・・ FROM <テーブル名> GROUP BY <列名1>,<列名2>,<列名3>,・・・ HAVING <グループの値に対する条件>
例(商品分類で集約したグループに対して、「含まれる行数が2行」という条件を指定する
SELECT shohin_bunrui, COUNT(*) FROM Shohin GROUP BY shohin_bunrui HAVING COUNT(*) = 2;
HAVING句に書ける要素
・定数
・集約関数
・GROUP BY句で指定した列名(つまり集約キー)
検索結果を並び替える(ORDER BY句)p107~
ORDER BY句を用いる
構文
SELECT <列名1>,<列名2>,<列名3>,・・・ FROM <テーブル名>; ORDER BY <並べ替えの基準となる列1>,<並び替えの基準となる列2>,・・・
例(販売単価の低い順、つまり昇順に並べる場合)
SELECT shohin_id,shohin_mei,hanbai_tanka,shiire_tanka FROM Shohin ORDER BY hanbai_tanka;
※ORDER BY句に書く列名は「ソートキー」と呼びます。
句の記述順序
SELECT句→FROM句→WHERE句→GROUP BY句→HAVING句→ORDER BY句
昇順と降順の指定
昇順に対して降順に並べる場合は列名の後ろにDESCキーワードを用います。
SELECT shohin_id, shohin_mei, hanbai_tanka, shiire_tanka FROM Shohin ORDER BY hanbai_tanka DESC;
この場合販売単価の高い順に並べます。
実は昇順に並べる際にもASCというキーワードがあるのですが、省略した場合は暗黙に昇順に並べるという約束になってます。
※NULLを含む列をソートキーにした場合、NULLは先頭又は末尾にまとめて表示されます。
※ORDER BY句では、SELECT句に含まれていない列や集約関数も使える。
楽々ERDレッスンでの学び
はじめに
今回は楽々ERDレッスンを読み学んだことを記していきます。
本書序盤はこれまで学んできたこと(キーとはなにか、エンティティとは何かなど)をビジネスの視点からより業務に近い形で説明がされております。
全体を通じて感じたのはデータベース設計で行う正規化はそれ自体が目的ではなく、あくまで手段であるということ。その業務・ビジネスの目的にそったデータベース設計を心がけることが大切なのかと感じました。正規化が目的化してしまうと厳格な正規化のルールを順守することに注力して、それを使う時の利便性や分かりやすさを損ねてしまう可能性があるので注意する必要があります。
序盤は私には難しいながらも読み進めていけましたが最も唸ったのは「実在する帳票からデータベース設計を行う」という箇所でした。
先の勉強で多少正規化の作法が分かってきたかなと思っていましたがとんでもなかったです。以下では私がやってみたデータベース設計と、それがどう不味かったのかを記していきたいと思います。著作権が怖いので、不味い箇所があればご指摘いただければ幸いです。
図書館の予約申込書編
以下は私がやってみた方法とテーブル設計になります。
1.この用紙の目的を検討する
「借りたい本の予約申し込みを行う」としました。
2.エンティティを抽出して主キーを追加する
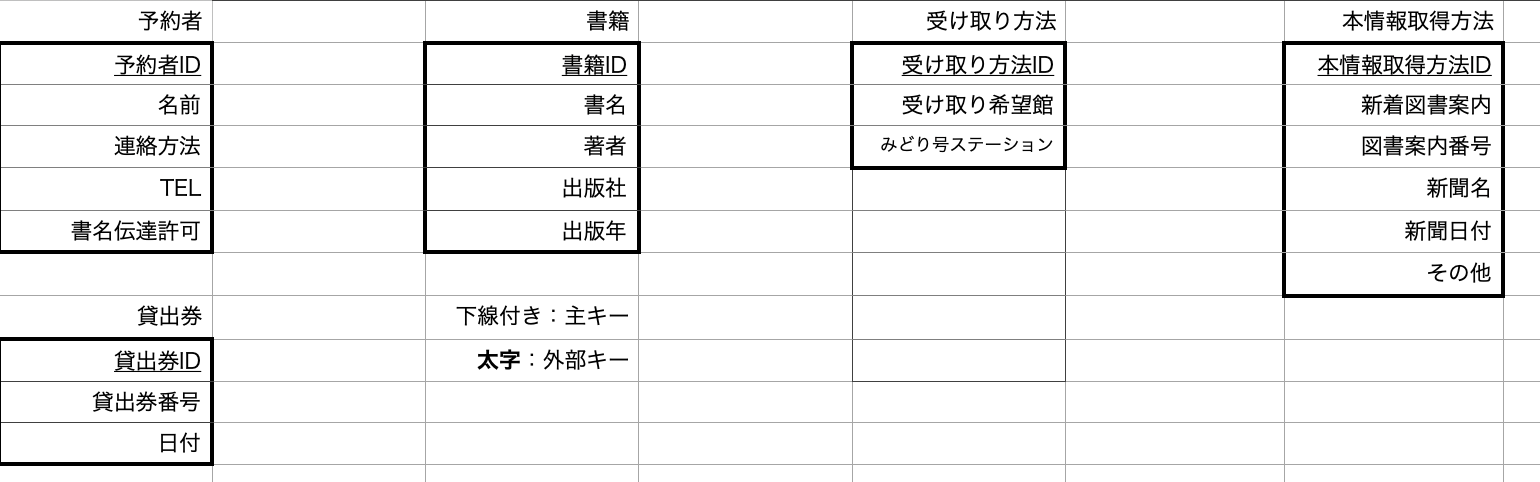
3.外部キーを設定しリレーションを組んでいく
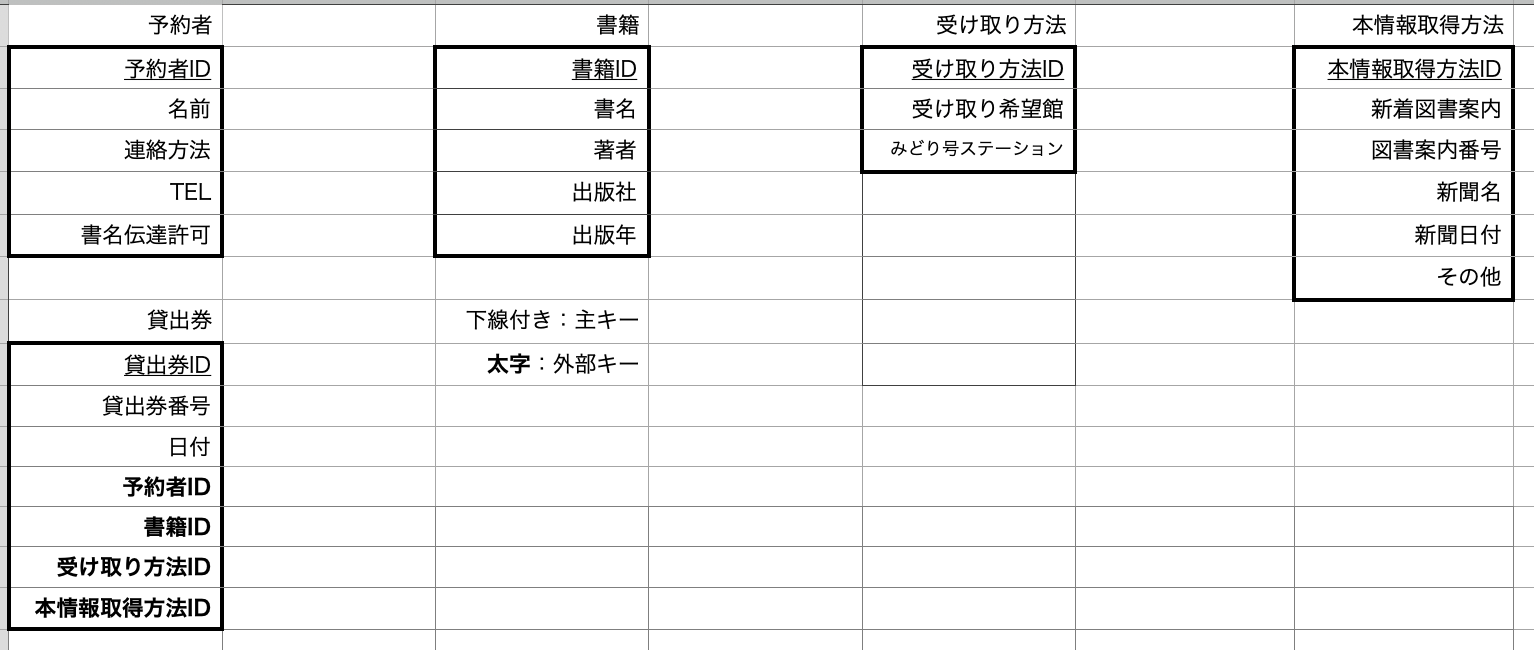
このように考えたのは貸出券に「誰が」「どの本を予約して」「どうやって受け取るか」という情報を付随させた方が良いと考えたからです。
では書内ではどのようなデータベース設計を行なっているか
書内では違ったデータベース設計を行っていました。これに私も納得したので気づきと共に記していきます。
まずは、最初の核となるエンティティの抽出から。書内では予約テーブルを抽出しています。
これは図書の予約申込書の目的が予約することなのだから当然です。私も目的を検討していましたがそれをエンティティとして抽出することに活かせていませんでした。
これをイベント系エンティティの抽出と呼びます。特徴としては「〜する」「〜日」と付けることができる点です。「予約する」「予約日」共に違和感ないので問題ないようです。
更にエンティティを抽出していきます。次に行うのはリソース系エンティティの抽出です。リソース系とは資産であることを指します。
今回でいえば「書籍」と「予約者」が当てはまります。予約書の発行者である図書館にしてみれば「書籍」は商品、「予約者」は顧客と考えることができ大切なリソース(資産)であることは間違いありません。(この考え方は本書を読むことで初めて意識しました。覚えておきたい考え方です。)
これで以下のエンティティができました。

この後はエンティティに項目(カラム)を入れていきますが、私が考えていたものと随分異なりますので一つ一つ確認しながら進めていきいます。
まずは予約者エンティティに項目を入れます。

ここで早速私の作成した予約者テーブルと異なる点があります。まずは「ふりがな」が入っている点。これは私が勝手に名前カラムと同一視していましたが、用紙にはきちんと「ふりがな」「名前」とそれぞれ記入する箇所ありますのでカラムとして入れるべきでした。
次に、予約者エンティティに「貸出券番号」が入っている点。私は貸出券テーブルを作成してそこに入れてましたが、書内では先程挙げたように「予約」「書籍」「予約者」をエンティティの主軸としておりますのでこの中で「貸出券番号」がどこに入るかを検討します。(どこにも入りそうにない場合はエンティティが不足している可能性あるので無理に入れる必要はありませんので注意)
書籍エンティティは書籍の内容が入るので除外するとして、予約エンティティはどうでしょうか?私としては最初このエンティティに入るのかと思いましたが、予約エンティティには予約の仕方・詳細が入るのだと考えると「貸出券番号」は少し違和感です。それよりも予約者エンティティに入れる方が良い気がします。感覚としては①貸出券番号は予約者に振り分けられる。②貸出券番号で予約者を判別するという点で他の名前・ふりがなカラムと同様の意味を持つ。
この辺の感覚で貸出券番号が予約者エンティティに入れられるのかと考えました。
次に書籍エンティティに項目を入れます。

ここでも私のテーブル設計と異なる点を見ていきます。
まずは価格のカラムが抜けていた点。これは私の見落としでしたので観察が足りませんでした。
次に出版社が別エンティティとして切り出されている点。これには驚きました。書内では商品カテゴリのようなものとして別エンティティに切り出したとあります。
ですが、私がこれまで学んできた正規化を行う際の検討事項である「1つのカラムには1つの値」「部分関数従属の解消」「推移的関数従属の解消」から考えると、今回の出版社エンティティの切り出しはどれにも当てはまらないように思えたのです。
実はこの後の補足で「出版社をただのメモ書き程度と考えるのであれば書籍エンティティに持たせるのも良い」とあるので必ずしも出版社を別エンティティとして切り出す必要はないのが分かります。
ここで大事なのは冒頭でも述べてるように、正規化はあくまで手段であるということ。その業務・ビジネスの目的にそったデータベース設計を心がけることが大切であるということです。これを踏まえた上で出版社を別エンティティとして切り出すのかを判断すべきです。
次に予約エンティティに項目を入れていきます。残るは申込日、連絡方法、電話番号、ご家族に書名を伝えて良いか、受け取り希望館またはみどり号ステーション、この本を何で知りましたか。になります。何が入るでしょうか?(ちなみにみどり号ステーションとは移動図書館のことです)
書内では以下のように設計しています。

申し込み日がここに入るのは違和感ありません。書名伝達可否は用紙の「ご家族に書名を伝えて良いか」を言い換えたものです。予約の詳細を入れたいのでこれも良いと思います。
では図書館エンティティはどうでしょうか。これは予約した本の受け取りを複数ある図書館のどこで行うかを選択させるということで別に切り出しています。ここから学べるのは複数の選択肢があり、そこから選択する場合は別エンティティで切り出してみるということです。
さて、ここでとあることに注目します。それは連絡方法(方法と電話番号)がまだ登場していないことです。私はノータイムで連絡方法と電話番号を予約者エンティティに含めました。ですが先の図書館の例を見るに連絡方法も選択式である以上、別エンティティに切り出した方が良さそうです。
では、電話番号はどうでしょうか?書内では以下のように設計しております。

この考え方(連絡方法と番号を別エンティティでそれぞれ切り出した)のポイントは予約者がいつも同じ連絡方法と電話番号を選択するかということだと思います。
いつも同じ方法、同じ電話番号でというのが確定しているのであればこれらは予約者エンティティに含めて良いと思います。ですが逆にいつも同じ連絡方法・電話番号とは限らない場合は「予約者は複数の連絡方法・電話番号を持つ」というように考えることができるのです。
また、ここで予約エンティティに「連絡不要区分」というのが新しく含まれていることに気づきます。これは用紙の連絡方法の中の選択肢の一つ「不要」という項目を表したものです。これがなぜ連絡方法エンティティと離れ、予約エンティティに入るのかを考えます。
そもそも何故予約したにも関わらず連絡不要とする可能性があるのでしょうか?
注目すべきはこの用紙のタイトル「予約(リクエスト)申込書」にあります。これはこの用紙の目的が
①依頼した本の予約が空いたら次に借りるから知らせてほしい(予約)
②こんな本があったら良いのではないか、置いてほしい(リクエスト)
の2つが存在することを意味します。②のリクエストの方は確かに本を取り寄せたとしても連絡は不要という人もいるかもしれません。そうすると予約者のところは記入が不要ではないかとの考えも出てきます。となるとこの連絡不要区分は予約の内容(予約なのかリクエストなのか)を明示するひとつの項目となりますので予約エンティティに入れることになると思われます。
最後に、「この本を何で知ったか」という項目について考えます。
これは私も「本情報取得情報エンティティ」として切り出していましたので少し安心しましたが、書内では「知った」というエンティティにしていました。
私はこれを貸出券エンティティに外部キーとして関連づけておりましたが、書籍をどのように知ったのかは人により異なるので書籍と予約者両方のエンティティに結びつくのが正解であると思われます。
最終的なテーブル間のリレーションシップ
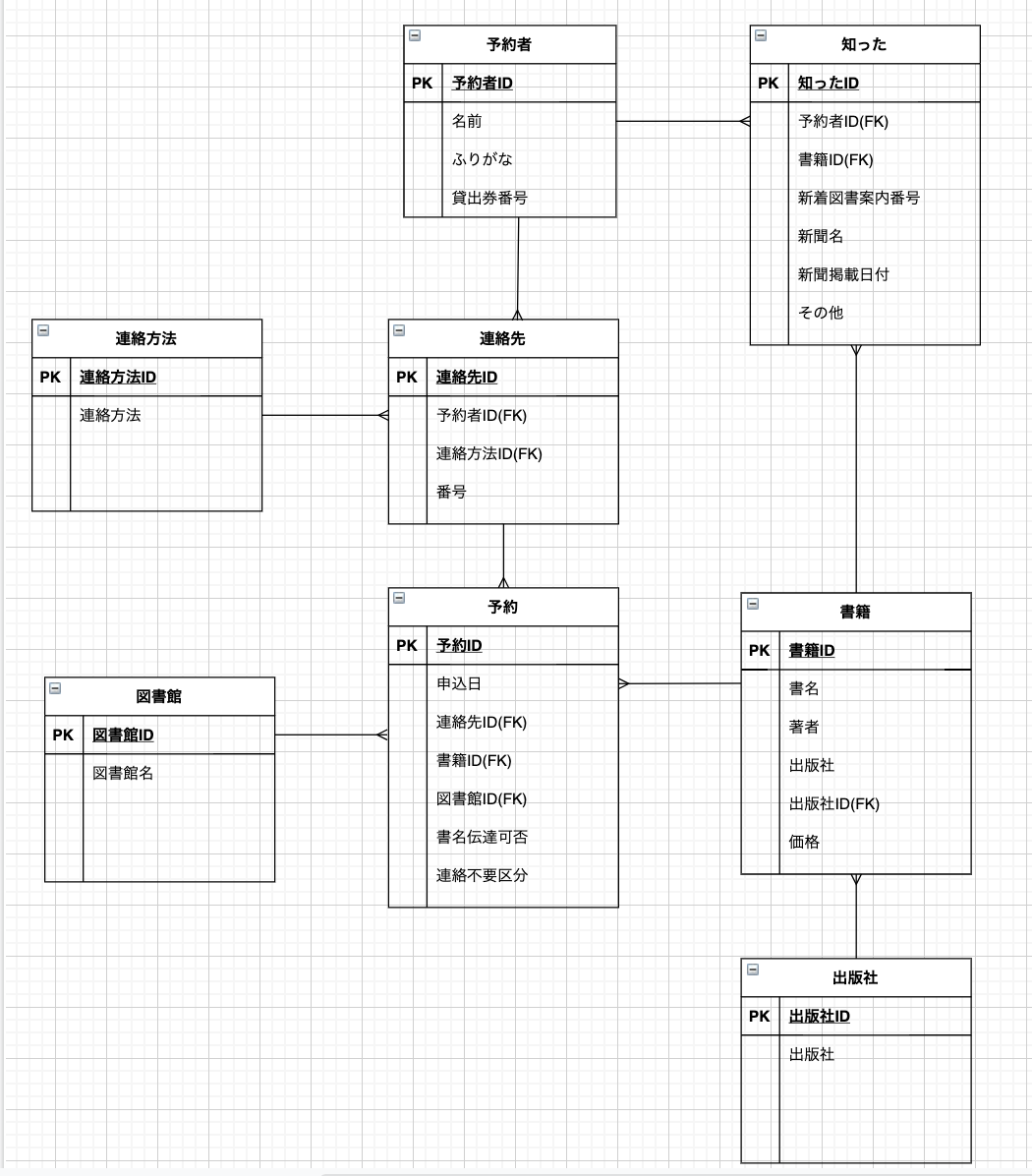
いかがでしたでしょうか。一番最初に完成系のER図を見ても理解が難しいかもしれませんが、一つ一つ順を追って見ていくと意外と理解できるのではないでしょうか?
私が最初に作成したものと比較すると複雑ですが、より業務内容に即したものであることが分かります。「予約する」という目的にも沿ったものであることも理解できます。
その点で私のやったことは目的が分からず良くないことが分かり、反省するばかりです。
今回の流れから正規化を目的とするのではなく業務・目的に沿ったデータベース設計が大切であることが実体験を持って知ることができました。
この他にも書内にて日常生活で遭遇する事象のデータベース化が記してありますので、読み返しながらより理解を深めていきたいと思います。
テーブル設計と論理設計
今回は学習中のテーブル設計と論理設計についてまとめてみます。
覚えておくべきワード
データベース設計:データベースは3層のスキーマ(枠組)からなる。
・外部スキーマ(ユーザーから見たDB、ビュー)
・概念スキーマ(開発者から見たDB、テーブル)
・内部スキーマ(DBMSから見たDB、データの物理的配置)
それぞれのスキーマは
「外部スキーマと概念スキーマ」
「概念スキーマと内部スキーマ」
の間で関連性を持ち、「外部スキーマと内部スキーマ」は直接関わることは無い。
外部スキーマと概念スキーマ:テーブルからセレクト文でデータを取り出す
概念スキーマと内部スキーマ:データファイルから人間にとっても分かりやすいテーブルという形で扱えるよう設定。
今回は主に概念スキーマについてのまとめになります。
主キー(プライマリーキー)
その値を指定すれば必ず1行のレコードを特定できるような列(の組み合わせ)。
テーブルにおいて必ず1つ存在する必要があり、かつ1つしか存在しない。(2つ以上のカラムで1つの主キーを構成することもある)
外部キー
2つのテーブル間の列同士の関連性を設定するもの
論理設計と物理設計
・論理設計(概念スキーマの設計)。要はテーブル設計。
・物理設計(内部スキーマの設計)。
正規形について
実在する事象をテーブル化していく時、正規化を行いながら矛盾のないテーブルを作成していく。
正規化は第1〜第5まであるが第3までやればほぼ第5正規化を行った形と同じものになるので第3まで解説、演習してみます。
第1正規形
「1つのフィールドには1つの値しか含まない」仮に1つのフィールドに複数の値があると主キーが特定の値を一意に定めることができなくなる。
第2正規形
「部分関数従属が解消されていて完全関数従属のみのテーブルとなっている状態」
といっても何言ってんだ?って感じだけど例えば
 という場合、主キーに会社IDと社員IDを置いているが会社名は会社IDのみの従属関係となるので部分関数従属となる。
という場合、主キーに会社IDと社員IDを置いているが会社名は会社IDのみの従属関係となるので部分関数従属となる。
これを解消する為に会社IDと会社名を別テーブルに切り出して完全関数従属のみのテーブルにすることが第2正規形である。
第3正規形
「推移的関数従属が解消されている状態」
これは何かというと複数の主キーから導き出されるカラムがあり、それに更に従属するカラムが存在している状態を解消しようということ。
第2正規形で提示したテーブルでも推移的関数従属が発生している。
会社IDと社員IDという2つの主キーから部署IDが導き出されるがそれに従属する形で部署名が同じテーブルにある。これが「推移的従属がある」ということ。
これを解消する為に部署ID、部署名は別テーブルに切り出してやる必要がある。
論理設計について
論理設計は以下の検討方法で行う。
[1]その事象が何をするためのシステムか?を検討する。これにより中心となるエンティティ(テーブル)が予測できる
[2]5W1Hに当てはめる「いつ、誰に、何を、どこで、なぜ、どうやって」
[3]インターフェース上の項目をカラムとして抽出、エンティティに当てはめる
[4]主キーと外部キーの設定(主キーとして適切なカラムがあるか探してみる。なければ自分で追加する)
[5]テーブルにおとしこみ正規形の条件が満たされているか確認する
これを踏まえて私が前職で使っていた「有償工事注文書」を用いて実際に論理設計をやってみる

[1]何をするためのシステムか?
契約した工事の内容を管理するシステム
[2]5W1Hに当てはめる。
今回は「いつ(日付)」「誰が(注文者)」「誰が2(担当者)」「何を注文(注文内容)」が大事だと思われるので、それぞれ「契約日テーブル」「注文者テーブル」「注文内容テーブル」「担当者テーブル」という形で中心となるエンティティ(テーブルを抽出)
[3]インターフェース上の項目をカラムとして抽出、エンティティに当てはめる。
今回のインターフェースからは
・日付
・注文者住所
・氏名
・電話
・担当者
・工事場所
・注文内容
・工期
・注文金額
が抽出される。それぞれエンティティに当てはめると
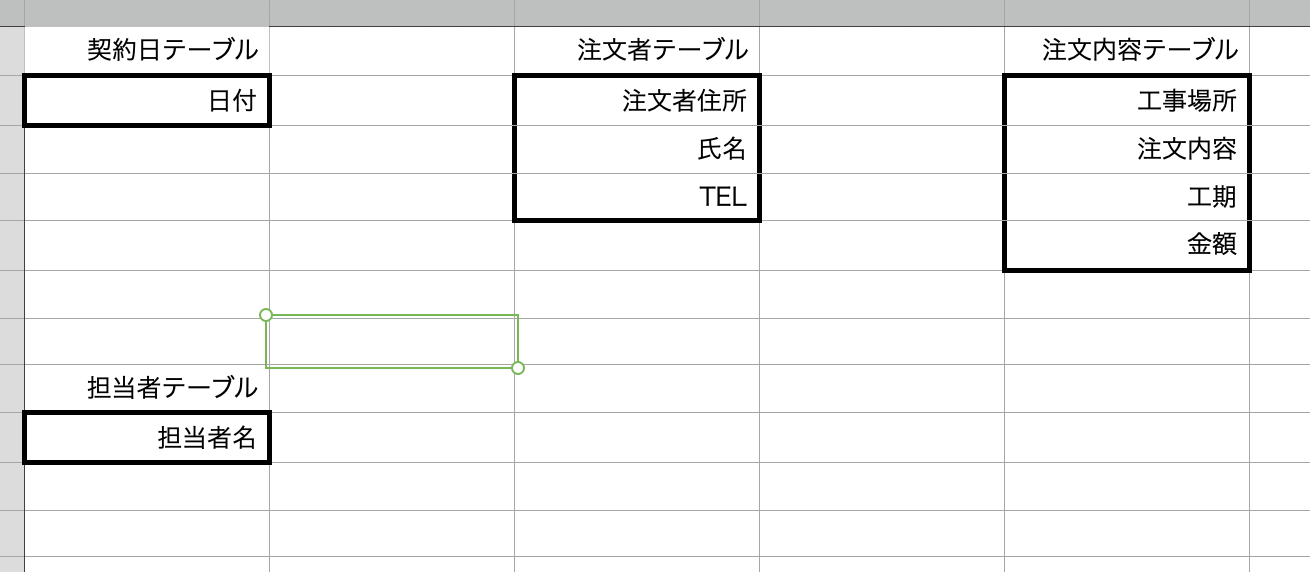
というようになる。
[4]主キーと外部キーの設定
まずは主キーに適切なカラムがあるか確認するが、どのカラムも一意でなく多様な値が入りそうなので適さない。その為、自分で主キーを追加する
主キーを追加したものが下記
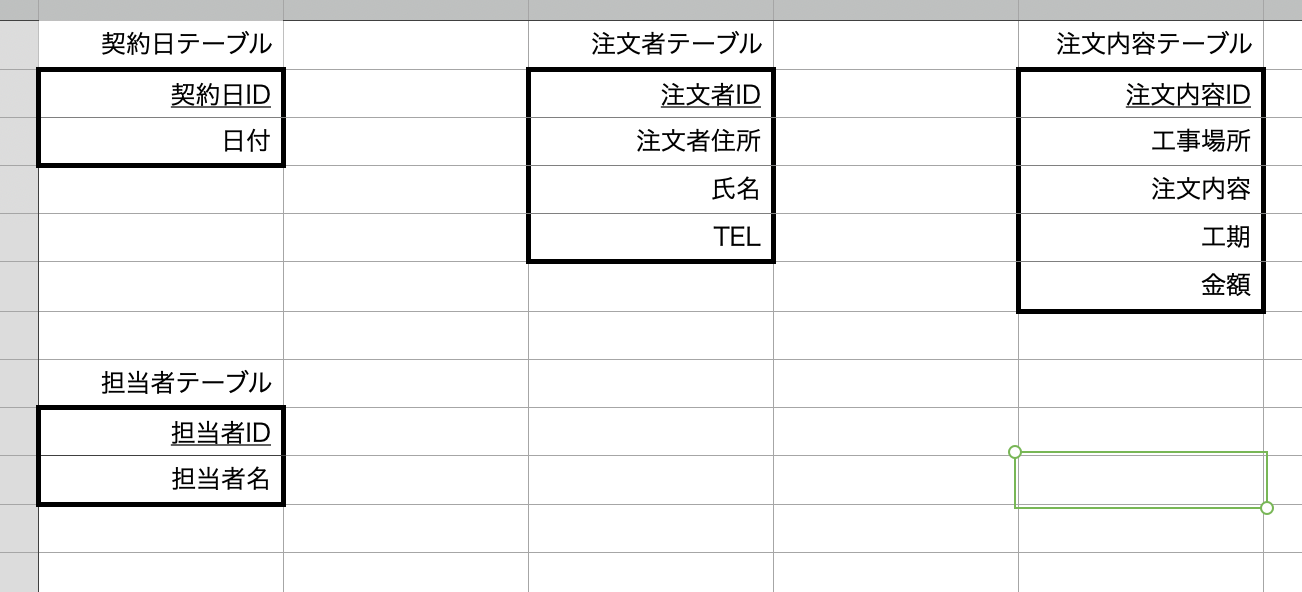
次に外部キーを設定するが、その目的はテーブル間の関係を持たせることなので、どのテーブル間でリレーション(関係)を持たせるべきか検討してみると
・注文内容にはいつ契約したか?の情報を含める必要がある
・注文内容にはどのお客様が契約したか?の情報を含める必要がある
・注文内容にはそれがどの担当者が担当するのか?の情報を含める必要がある
これらを踏まえると以下となる

[5]テーブルに落とし込み正規化が満たされているか確認する
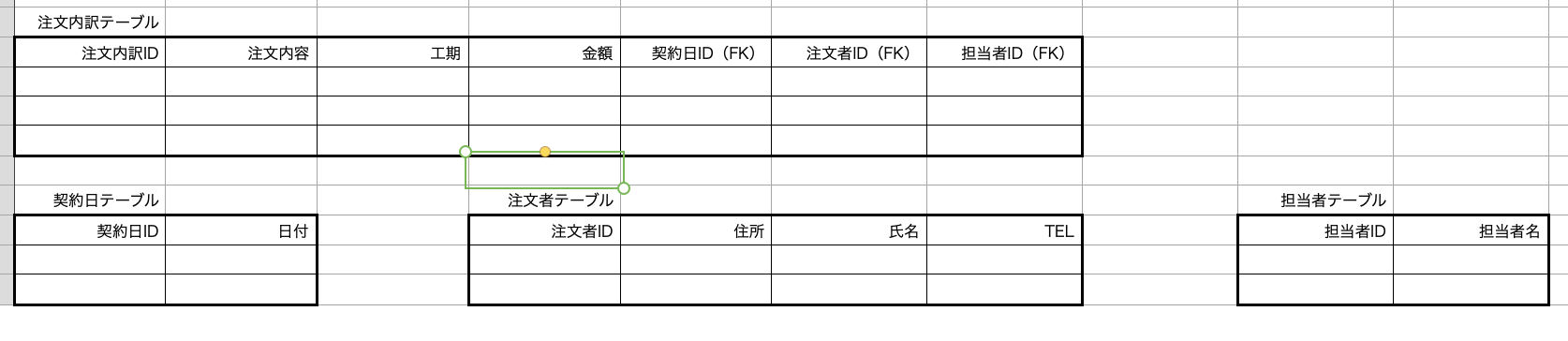
これは先述した第1〜第3正規化を満たしていると思われるのでok。
これをER図に図示すると以下となる
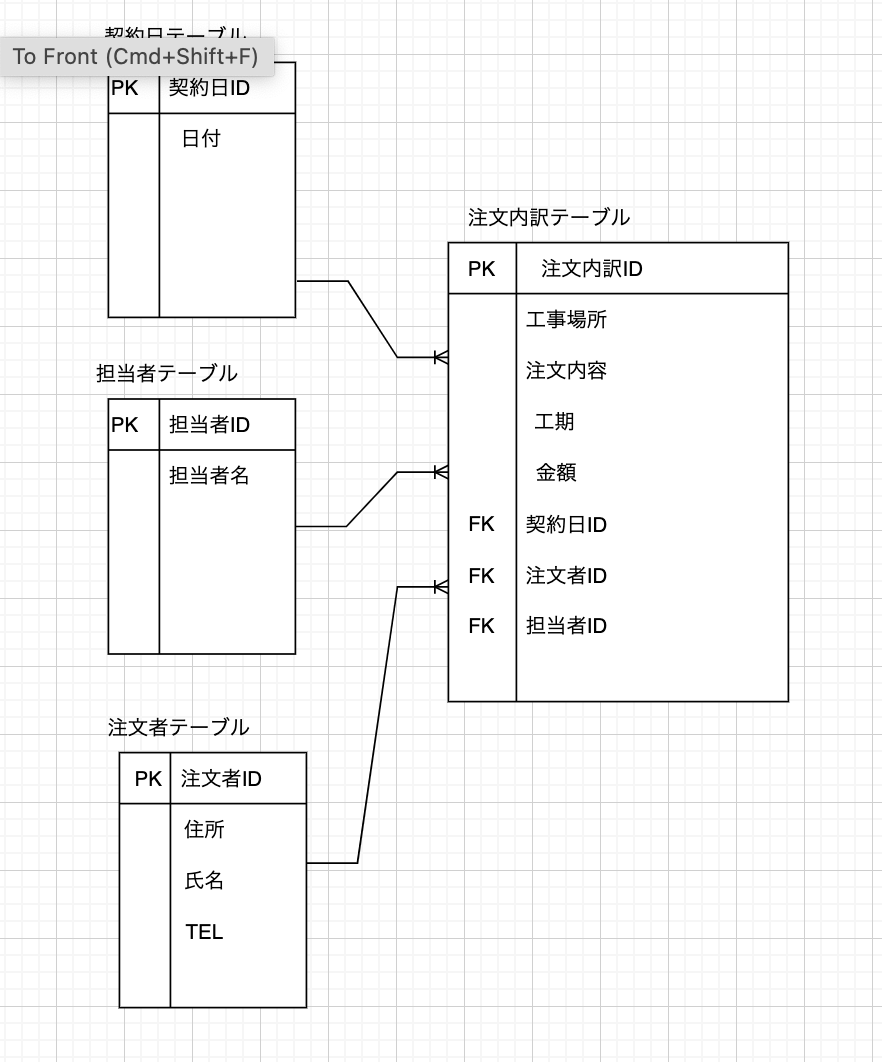
上記のようにした理由としては注文内訳テーブル内で外部キーにより参照した他のテーブル(契約日、注文者、担当者)のカラムは今後複数出てくる(内包する)可能性があるので
契約者、注文者、担当者各テーブル:注文内訳テーブル = 1:Nとした。
まとめ
今回私が例として行った論理設計では学習教材で行ったものとは少し違う形となった。間違ってるかもしれないが今は本記事のように考えているので,さらに学習を進めて後日訂正する可能性はあると思う。
コンビニレシートから学ぶデータモデリング手法を拝読して
【DB設計入門|ER図|MySQL】コンビニレシートから学ぶ!データモデリング手法 https://engineers.weddingpark.co.jp/mysql-database-design/
はじめに
今回は、理解する為には元記事内の図を参照する必要がある点と、元記事を見ながら実践で他課題を進めた方がより深い理解に繋がると思うのでここではポイントや覚えておきたい点を備忘録として記載します。ポイントを押さえておけば自分の言葉でも説明できるくらいには理解できたと思います。
データモデリングとは:ある方法論に従ってデータを構造化していくことであり、狭義にはリレーショナル・データベースの関連モデルになる。
ポイント1
元記事で紹介しているデータモデリング手法の目的を覚えておくことが大事です。今回の目的は「ある特定の日のレシート一覧を出力できるシステム」のデータモデリングを行うことになります。
ポイント2
概念のパズル化を行う最中で「日時」の項目を入れようとしますが、その時のパズルには当てはまりません。この感覚が大事で、現状では何か概念自体が足りていないということを示しています。その際は、概念の追加をしてみることで宙に浮いていた概念が当てはまることがあります。
ポイント3
次に「商品」という概念をパズルに当て嵌めようとした際、「店」という概念の中に直接当て嵌めようとすると「店の商品」となってしまいました。今回はポイント1で述べたように「ある特定に日のレシート一覧を出力できるシステム」のデータモデリングを行うのが目的であるため、「店の商品」では本来の概念とズレてしまいます。
パズルの各概念は全て実体で考えるようにしましょう
「商品」がレシートの背景にある「物を買う」という行為(ストーリー)の中で関係を持ったのはどの場面だったでしょうか?それは[店員]が販売した場面(もしくは[客]が購入した場面)ではないでしょうか?
この文はとても丁寧に考え方の流れを示していると思いましたのでそのまま記載しました。
自分自身を言葉で言い換えると、目的・機能のシミュレーションを行い、概念の正確な「起こり」を捉えてパズルに当てはめるのが大事であると思いました。
最後に
この後、完成させたパズルを元にERD図に当てはめていくという作業が元記事内で行われていきますが、とても分かりやすいので元記事を何度も見て理解しようと思います。
また、元記事を見ながら自分のポートフォリオのデータモデリングを行い、近日アウトプットしてみようと思います。